
Today we will discuss the internal structure of an executable or exe file. This article is very important because it will clear up some of the concepts about different sections of executable files. You will find useful information during reverse engineering, or debugging, any application. From a high level viewpoint, an exe file only looks like a single file, but actually consists of several parts. A hacker must understand each part and its use in every different section of an exe file.
 |
| Exe Internal Sections |
When debugging an exe file, people often notice strange looking things that appear without understanding what they are, so they close the debugger. After reading this article, you will understand what they are and how to use them.
The sections that are most commonly present in an executable are:
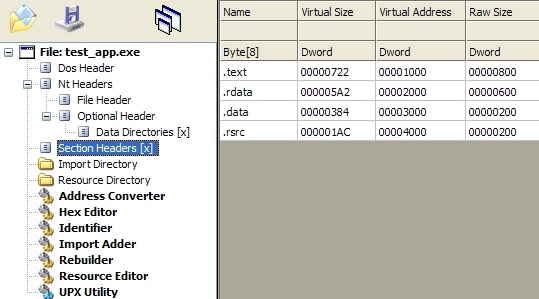
- Executable Code Section, named .text (Microsoft) or .txt (olydbg) or CODE (Borland)
- Data Sections, named .data, .rdata, or .bss (Microsoft) or DATA (Borland)
- Resources Section, named .rsrc
- Export Data Section, named .edata
- Import Data Section, named .idata
- Debug Information Section, named .debug
Note: the structure of a PE (portable executable) file on a disk is exactly the same as when it is loaded into memory, so if you can locate that information in the file on the disk you will be able to find it when the file is loaded into memory.
However it is not copied exactly into memory. The windows loader decides
which parts need mapping-in and which parts have to be omitted. Data that is not mapped-in is placed at the end of the file past any parts that will be mapped-in e.g. Debug information.
which parts need mapping-in and which parts have to be omitted. Data that is not mapped-in is placed at the end of the file past any parts that will be mapped-in e.g. Debug information.
Lets understand the detailed meaning of all sections:
1. Executable Code Section
In Windows, all code segments reside in a single section called .text or .txt or CODE. Since Windows uses a page-based virtual memory management system, having one large code section is easier to manage for both the operating system and the application developer. This section also contains the entry point (EP) and the jump thunk table (where present) which points to the IAT.
Note:
a. EP is the entry point from where the code section starts in obfuscated exe file.
b. Jump thunk table: contains all the jump addresses and references.
c. IAT: This stands for import address table, this is a table of function pointers filled in by the windows loader as the dlls are loaded. I will post a complete tutorial for Import address table because its a very important concept. For now just take it as table containing function pointers.
2. Data Section
The .bss section represents uninitialized data for the application, including all variables declared as static within a function or source module.
The .rdata section represents read-only data, such as literal strings, constants, and debug directory information.
All other variables (except automatic variables, which appear on the stack) are stored in the .data section. These are application or module global variables.
The .rdata section represents read-only data, such as literal strings, constants, and debug directory information.
All other variables (except automatic variables, which appear on the stack) are stored in the .data section. These are application or module global variables.
3. Resource Section
The .rsrc section contains resource information for a module. There are many
resource editors available today which allow editing, adding, deleting, replacing, and copying resources.
resource editors available today which allow editing, adding, deleting, replacing, and copying resources.
4. Export Data Section
The .edata section contains the Export Directory for an application or DLL.
When present, this section contains information about the names and addresses of exported functions.
When present, this section contains information about the names and addresses of exported functions.
5. Import Data Section
The .idata section contains various information about imported functions, including the Import Directory and Import Address Table. The import section contains information about all the functions imported by the executable from DLLs. This information is stored in several data structures. The most important of these are the Import Directory and the Import Address Table which we will discuss next. The Windows loader is responsible for loading all of the DLLs that the application uses and mapping them into the process address space. It has to find the addresses of all the imported functions in their various DLLs and make them available for the executable being loaded.
6. Debug Information Section
Debug information is initially placed in the .debug section. The PE file format also supports separate debug files (normally identified with a .DBG extension) as a means of collecting debug information in a central location. The debug section contains the debug information, but the debug directories live in the .rdata section mentioned earlier. Each of those directories references debug information in the .debug section.
7. Base Relocation Section
Last but not the least, the most important section from the hacker’s perspective. When the linker creates an EXE file, it makes an assumption about where the file will be mapped into memory. Based on this, the linker puts the real addresses of code and data items into the executable file. If, for whatever reason, the executable ends up being loaded somewhere else in the virtual address space, the addresses the linker plugged into the image are wrong. The information stored in the .reloc section allows the PE loader to fix these addresses in the loaded image so that they’re correct again. On the other hand, if the loader was able to load the file at the base address assumed by the linker, the .reloc section data isn’t needed and is ignored.
We will continue our reverse code engineering tutorials in future classes.
Leave a Reply