

Machine learning is transforming cybersecurity by enabling the detection of phishing attacks, where attackers deceive users to steal sensitive data. By analysing patterns in emails and behaviour, machine learning algorithms can quickly and accurately identify phishing attempts, providing a powerful defence against these evolving threats.
In this article, we will see a roadmap of how we can develop a system that can be used to identify phishing websites. I must mention here that the end goal will not be perfect as this is a continuous process. Let us see what steps are required to create this system.
High Level System Details
- Identifying Features: Determine the key characteristics that distinguish legitimate websites from phishing sites.
- Building a Benign Website Dataset: Compile a dataset of legitimate websites to evaluate and extract relevant features.
- Building a Phishing Website Dataset: Gather a dataset of phishing sites to identify and extract malicious features.
- Model Training: Train a machine learning model using the datasets to determine patterns that differentiate between benign and phishing websites.
- Developing a Python Proof of Concept (POC): Create a Python script that serves as a practical demonstration of the phishing detection system.
Features Selection
The critical aspect of the system lies in determining the features that help classify a website as phishing or benign. This process involves staying updated with the latest research and studies on phishing detection. Below, we will outline some examples of key features that can be used to distinguish between legitimate and phishing websites, drawing from recent findings and best practices in the field.
Domain Registration Time
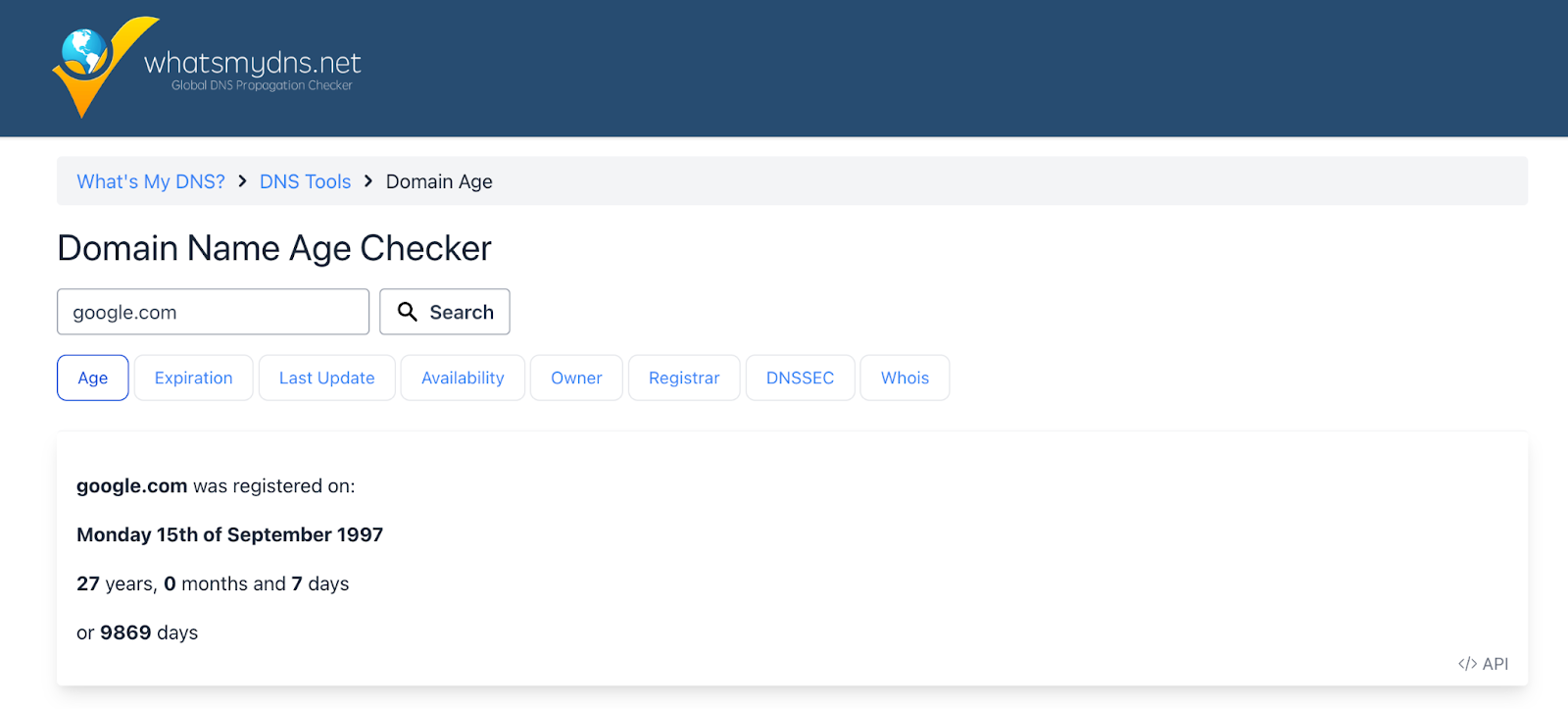
Threat actors frequently register new domains to support phishing campaigns, often using deceptive or misleading URLs that closely resemble legitimate websites. By quickly setting up and discarding these domains, attackers can evade detection systems and black listings. These domains are often used for a short time, sending phishing emails or hosting malicious content, before being replaced with new ones, making it challenging for traditional security measures to keep up with their rapid rotation and evolving tactics. So this can be a feature of a system that checks the time of the domain registration and rejects the domains that are newly created. For example, we can check registration time of “google.com”
Use of IP Address in Place of Domain
If a URL uses an IP address instead of a domain name, such as “http://xx.xx.xx.xx/fake.html,” it’s often a strong indicator of a phishing attempt aimed at stealing personal information. In some cases, cybercriminals go a step further by encoding the IP address in hexadecimal format, like “http://0xaa.0xaa.0xaa.0xaa/paypal.ca/index.html,” to further obscure their intent and evade detection. These tactics are designed to deceive users into believing they are visiting legitimate sites while masking the true nature of the malicious link.
Long URLs to Conceal Suspicious Elements
Another common tactic used in phishing attacks is the use of excessively long URLs to hide malicious components. For instance, an attacker might use a URL like:

The legitimate-looking parts of the URL are placed upfront, while the suspicious part is buried within a long string of parameters, making it difficult for users to spot the threat. Studies show that URLs longer than 54 characters are often associated with phishing attempts. In one dataset, nearly 48.8% of URLs that were 54 characters or longer were classified as phishing, underscoring the significance of URL length in phishing detection.
Use of URL Shortening Services
Phishers frequently exploit URL shortening services like TinyURL or Bit.ly to disguise malicious URLs. These services create short, seemingly harmless URLs that redirect users to phishing sites. For example, an original URL like “http://example.com/fake-login.html” could be shortened to “bit.ly/abc123,” making it difficult for users to recognize the malicious intent. Since phishing URLs often rely on redirection, shortened URLs should be treated with caution, as they are frequently linked to phishing activities. Lets see an example, below is the image of the url that was processed through the url shortening service.
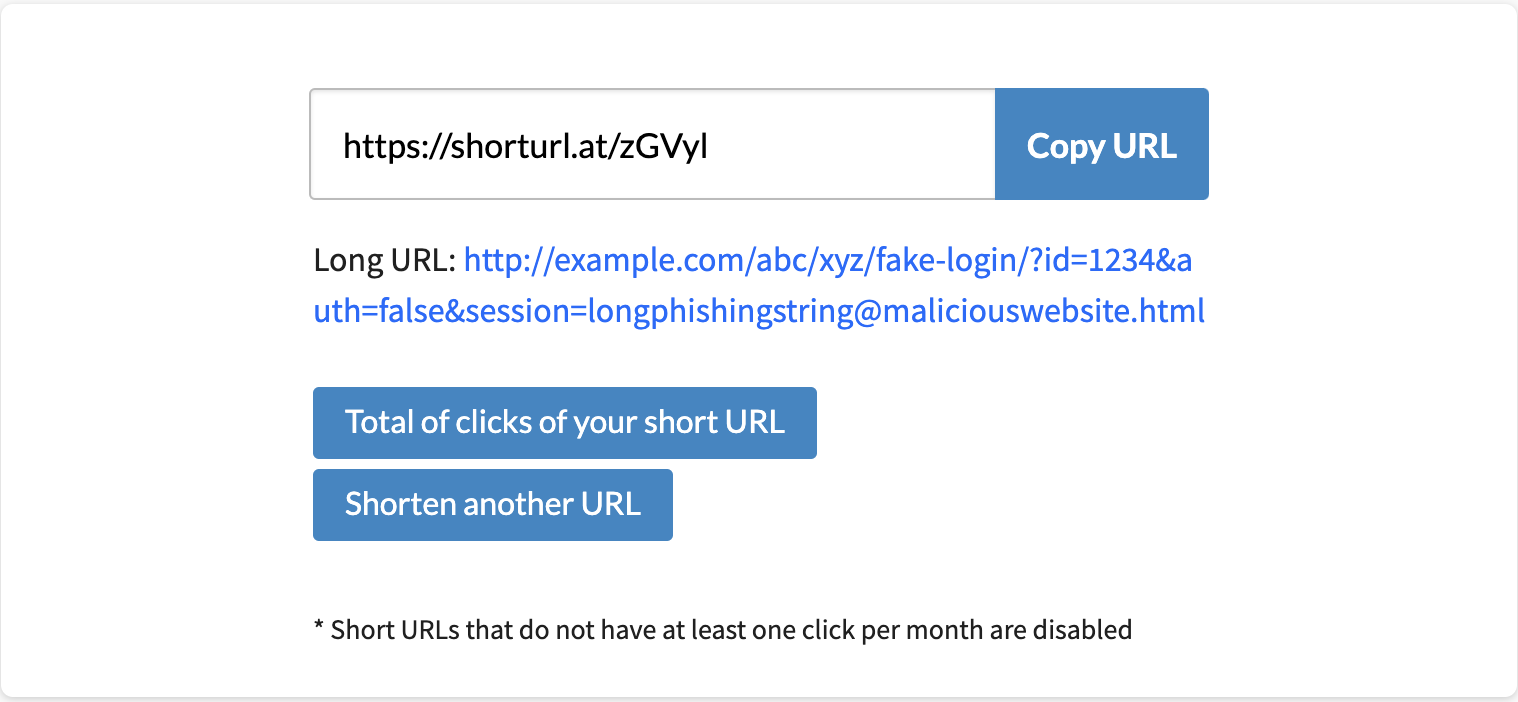
The idea is to get these kinds of features that can help us in deciding whether the website we are going to visit is safe or not. Next step is to prepare a dataset to train our model.
Preparing DataSet
To prepare our dataset, we can write a python script that can take a url and fetch the required features for us. We need to store the features of a website in a text file that we can process later on.
Benign Websites
For benign websites, we can use Alexa top 1 million websites’ list from “kaggle”. The link to website is below
https://www.kaggle.com/datasets/cheedcheed/top1m
Phishing Websites
To get the data of phishing websites, we can use multiple websites that keep track of phishing campaigns and add the websites links in their database so that users can get advantage of it. One example of this is to use Phishtank. The link if below
Idea of Scripts for Getting Features
The script will be used for preparing our dataset and we can use the same code to prepare our POC as well. Let us explore how we can use python for extracting features.
Let us take first the example of Alexa top 1 million websites. It is a “.csv” file. So here is the pseudo code kind of steps
- Open the file
- Read each line containing website URL e.g. google.com
- Follow the website using web scraping tools like scrapy/BeautifulSoup
- Fetch the required features from webpage
- Store the fetched features in a file in binary form
- Train the model on the data
- Use trained model in POC
When It comes to writing code for extracting features, let us see an example on how we can write code for them.
Code to Check if IP Address is Valid
In the below snippet, we check if the URL provided is actually a URL or an IP address. The idea is that if a website is using IP instead of a proper domain name, there can be something phishy behind it because businesses cannot rely on IP addresses. Then we check if the provided url is not hex coded, if yes then again it’s not normal.
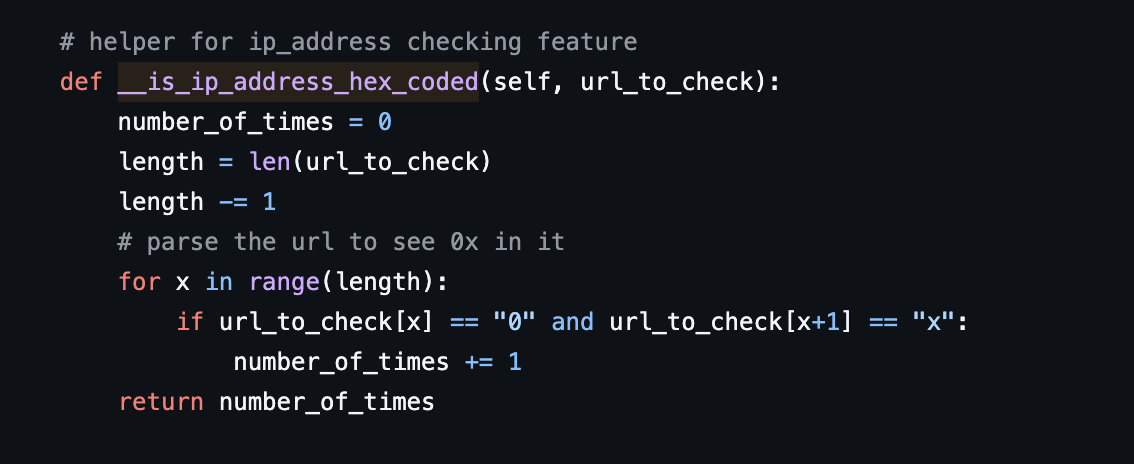
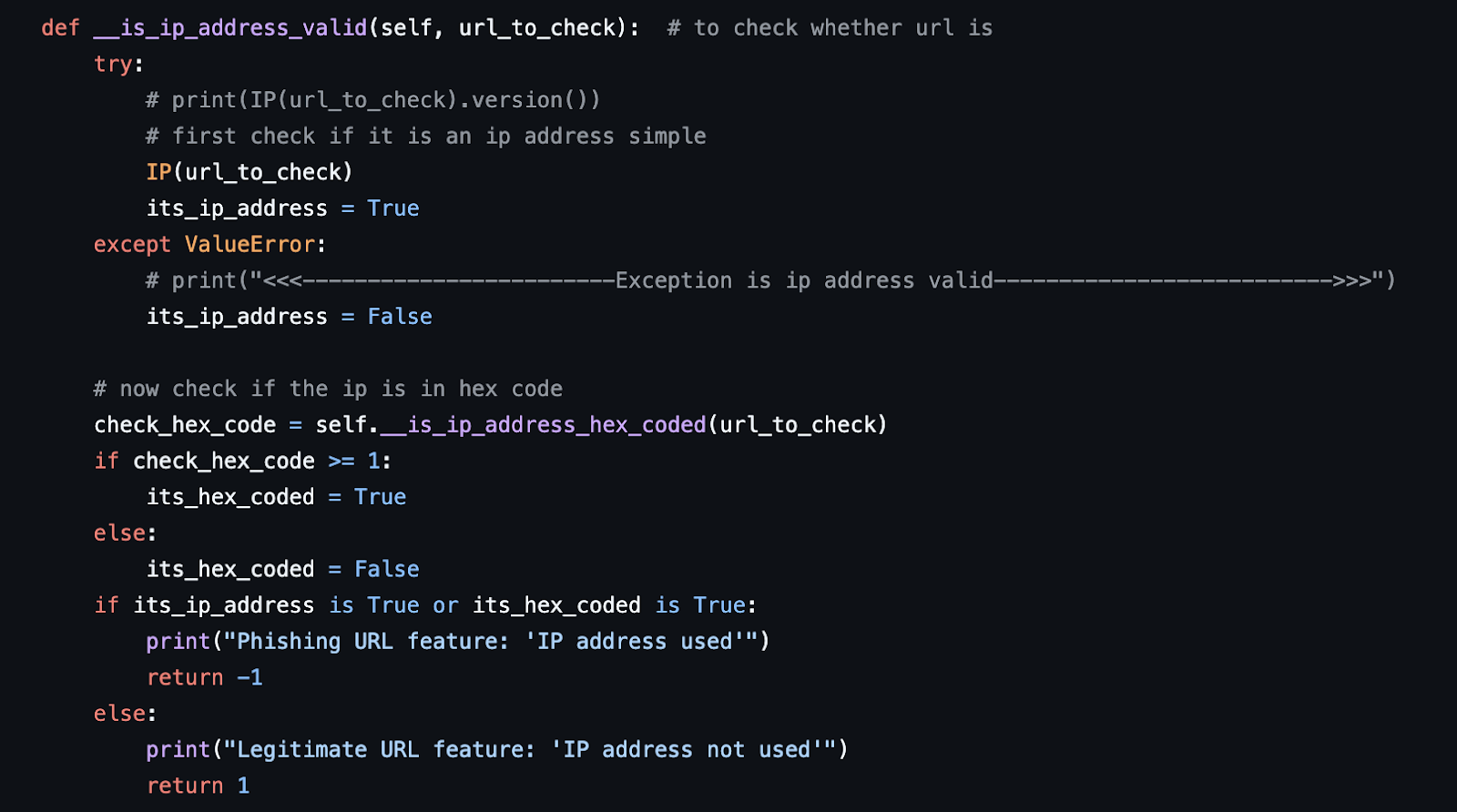
The output of the function can be one of two options:
- [1] – If we decide that URL provided is not phishing url we set the value of the feature to [1]
- [-1] – If we think that URL is phishing, we set the value to [-1]
Just like the above example, we prepare our dataset of benign and malicious websites and store it in a text file for later use.
Training the Model
The next step is just a high level overview of what to do with the dataset. Once we get our dataset, we need to decide which supervised learning algorithm we can use to train our model. There can be multiple options like
- Decision Trees
- Support Vector Machines
- Random Forest
And many more. We will leave up to you how you train your model. The idea to use supervised learning algorithms is that we can tell the model that if certain features are in a website then its a benign or phishing website. When we extract all features of a website, its data will look something like
1,-1,1,-1,1,1,1,1,1
In the above line, the first 8 digits show the features of the website that we decide on, and the last one is the actual specification whether a website is phishing or bening. In our dataset, we can write that on our own because we know when we are going through links of phishing websites or when we are parsing benign websites. One thing I must mention here is that the above explanation is all based on just examples. In actuality, the number of features will be depending on what you prefer.
Refining the Model
A good practice in training AI models is to refine the models with the passage of time with updated data and remove the features that are not contributing very well. One way of doing it is to minimize the entropy.
Entropy
Entropy in supervised machine learning measures the uncertainty or randomness in a dataset, specifically how mixed or impure the data is with respect to the target classes. In decision trees, entropy is minimized by selecting features that split the data into purer subsets, reducing uncertainty. To minimize entropy, algorithms like information gain or Gini index are used, which help choose features that create clearer distinctions between classes. Lower entropy leads to more confident predictions and better model accuracy.
Creating Proof of Concept
As a POC, we can create a python application that includes our model. In our application, we can add a few more steps to make it more efficient and quick. Here are steps are application will take in a run
- User provides a URL to application as input
- Application checks the reputation of the URL & its associated IP with third party sources and if it is bad, we give the result to the user and don’t go further thus giving a quick decision and accuracy. Now, why this is good, let me explain it afterwards.
- If we don’t find the result from third party tools, we then process the website
- Extract features from website
- Load the model and provide features to it
- Based on value returned, make a decision for the user
Introducing Third Party APIs for Quick Decision
We can integrate some tools in our application for better working. For example, PhishTank is a website that flags the websites as phishing ones when people report the websites. We can rely on it as human intervention is present in this process.
Similarly, we can check the associated IP address with the domain if it is blacklisted or abusedIP and warn the user right away.
Let us see some code that can be helpful. It’s an example code that may contain issues.
Function to Use AbuseIPB
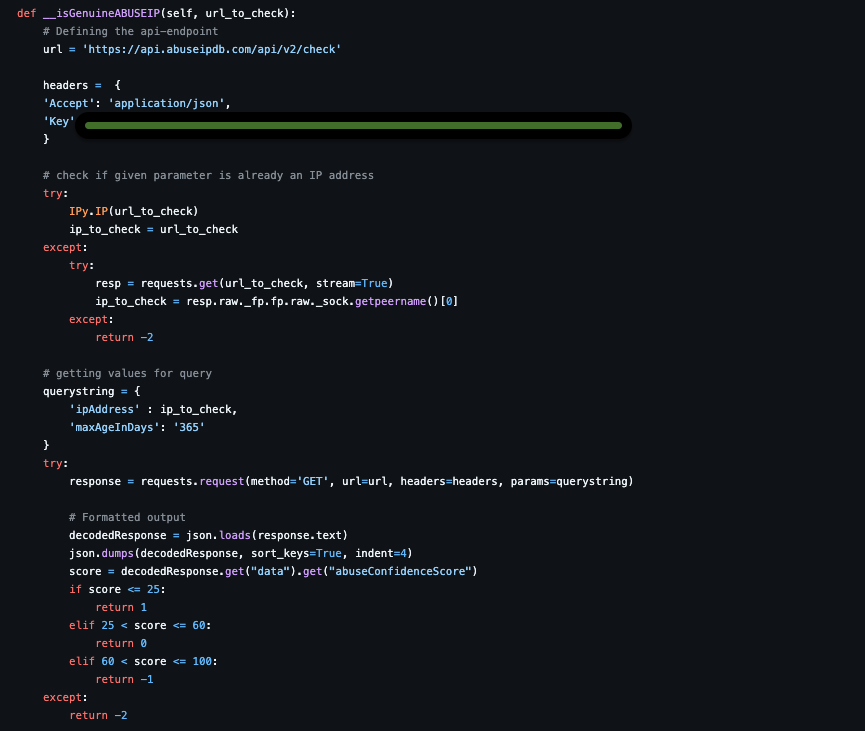
Function to Use PhishTank
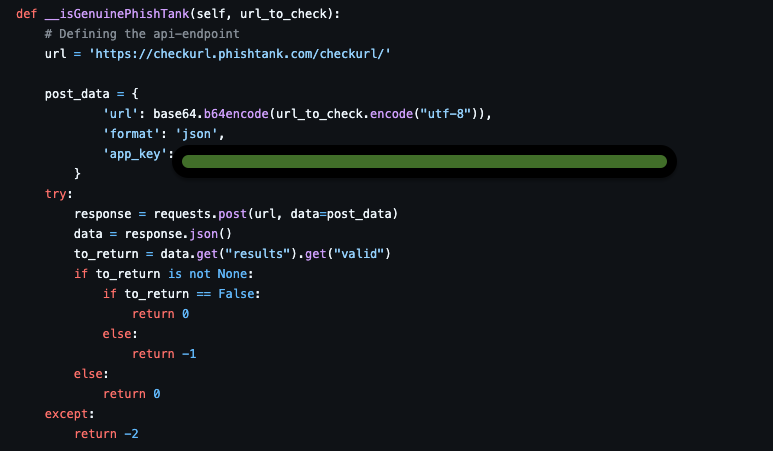
Decision Making
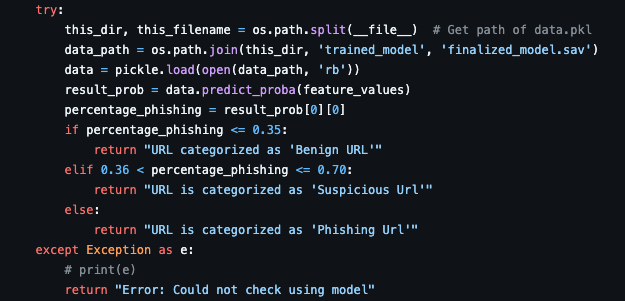
In the end, when we want to make a decision for the user, we will try to keep it less strict. Suppose our model gives us a number from 0 to 1 where 0 being bening and 1 being phishing. We can divide it in a range to provide lenient results. For example, we can say that when the value is within range of 0 to 0.35, it’s a benign website. When it’s between 0.35 to 0.7, it’s a suspicious URL so that users can take a look at it with more care. And if the value is greater than 0.7 then it’s a phishing website.
The code for this can be like
In this article, we go through a basic system that can be used to differentiate between benign and phishing websites. The system will be developed properly after identifying features from research articles, creating dataset of both benign and phishing websites for training of machine learning algorithm model and creating a POC application in the end with integration of apis that can help us in making a decision at an early stage for the users.