
No matter how much care you take during development of any software, security issues creep in. Hence, it is important to get the code reviewed for security loopholes. Code is the only advantage for organizations over the hackers and they need to utilise this fact in a planned way. Relying only on penetration testing is definitely not a good idea. When you have the code, use the code! So How to Identify Vulnerabilities in code ? Let’s learn!
Most organisations today rely on commercial tools such as IBM Appscan, HP Fortify etc. for code reviews. These tools scan the entire code and locate potential issues by looking for use of certain APIs and functions within the code. The security reviewer then needs to manually verify these issues and confirm the findings. This approach definitely saves time if you can afford the license cost. It also involves the risk of not identifying all the potential issues (as is the case with any tool). Without the help of a tool, the reviewer has to understand pages/locations of interest and verify the code. In any case, reviewing the code and identifying the issue has to be done manually. In this article, we will focus on how a security professional can identify some of the most common vulnerabilities within an application. Below are the common steps involved while performing a code review at a high level:
Identify the objectives of review:
Reviews are much effective with objectives in place. Below are some of the questions that help you to understand the objectives of your review:
- What is the scope of the review?
- What are the technologies used in the application?
- What are the vulnerabilities against which the code will be reviewed?
Identifying areas / components of interest:
Identifying important components needs to be done with the help of development team. For example, identifying components that handle authorization, sessions etc. can be done at this stage. Having a proper understanding about what the application is about and what it handles would definitely help the reviewer to connect certain dots while performing the review. Consult the development team to know about applications functionality, features, and architecture and so on. Learn More about how to identify entry points in detail (click here).
Reviewing the code:
Perhaps this is the most important and heavily weighted part compared to the other steps. Automated source code scanners are commonly used for code analysis. They scan the code and present the reviewer with thousands of identified findings that may be valid or false positives. It is now up to reviewer to figure it out by actually reviewing that piece of code. The point is that in spite of using automated tools, it is still essential to perform manual review. For remaining part of the article, we will discuss in detail about how code can be reviewed to identify potential issues.
Reviewing the code for a particular vulnerability boils down to looking for key pointers related to that vulnerability within the code. It entirely depends upon what vulnerability you are looking for. For instance, the approach that is used for reviewing XSS would be very much different from the one used for SQLi. Although it would be desirable to manually review every line of code comprehensively, it is not possible in real world especially with large applications. Hence, it is important to have a perspective about what to find in the code – What am I looking for in this piece of code?
There are two types of techniques to run through the code during code analysis:
- Control flow analysis
- Data flow analysis
Control Flow Analysis: As part of control flow analysis the reviewer sees through the logical conditions in the code. The reviewer looks at a function and identifies various branch conditions such as loops, if statements, try/catch blocks etc. He will then figure out under what circumstances each branch is executed. While performing the control flow analysis, below are some of the questions (these are only a sample) that a reviewer needs to consider.
- Does the application rely on client side validation?
- Does the application embed sensitive information (such as passwords) in the code?
- Is sensitive data being stored in predictable locations (such as temp files), or being sent in clear text over the network?
- Is there proper and consistent error checking?
- Do error messages give away too much information?
- Does the application expose sensitive information via user session?
Data Flow Analysis:
Dataflow analysis is the mechanism used to trace data from the points of input to the points of output. This will help you find bugs associated with poor input handling. This is the technique commonly used to identify several issues such as cross-site scripting, SQL injection etc. Below are the steps involved in this process:
- Identify the source of input. Determine whether it is trusted or untrusted. Any data coming from the user is considered to be untrusted input.
- Trace the flow of data to each possible output. Look for any data validation snippets involved in this path.
- Identify where the data finally ends up.
While doing the data flow analysis, although the approach remains same, the analysis depends on underlying vulnerability. For example, let us consider the case of cross-site scripting to see how data flow analysis is done. In the case of XSS, we mainly look for certain APIs that interface with the external world. To explain in simple terms, cross-site scripting involves two things – Accepting input from user and displaying it back. Hence, there are two steps that we need to do while reviewing the code for XSS:
Step 1: Identify ‘source’: Look for those API’s that are used to accept data from external sources. Identifying the potential sources is done by looking for various API’s that are used to accept the data. For example below are the key areas to look for when dealing with ASP.NET:
Accepting User Input [Commonly used]:
request.form
request.querystring
request.url
request.httpmethod
request.headers
request.cookies
TextBox.Text
HiddenField.Value
Accepting User Input [Others]:
InputStream
request.accepttypes
request.browser
request.files
request.item
request.certificate
request.rawurl
request.servervariables
request.urlreferrer
request.useragent
request.userlanguages
request.IsSecureConnection
request.TotalBytes
request.BinaryRead
recordSet
Step 2: Trace the flow: The above functions can be the ‘source’ of unvalidated data. Here we need to figure out if the application is performing input validation on the data before processing it. If blacklisting is done for certain values like script etc. then there is always a chance to bypass them.
Step 3: Identify the ‘sink’: Once we identify the source, we then need to understand what the application is doing with this data. Problems would arise if the application directly displays this to the user (reflected xss), or if it stores this in database and displays it at a later point of time (stored xss). Hence, the next step is to identify those functions that are used for sending responses to the client. For example below are the functions that are commonly used in ASP.NET to send responses to the client. These are called ‘sinks’.
Sending Response [Commonly used]:
response.write
<% =
Lable.Text
HttpUtility
HtmlEncode
UrlEncode
innerText
innerHTML
If the application output encodes the data (for example with the use of functions such as HtmlEncode), then it is considered to be safe. Automated scanners do this job of identifying sources and sinks effectively and offer a clear view as shown in the below figure:
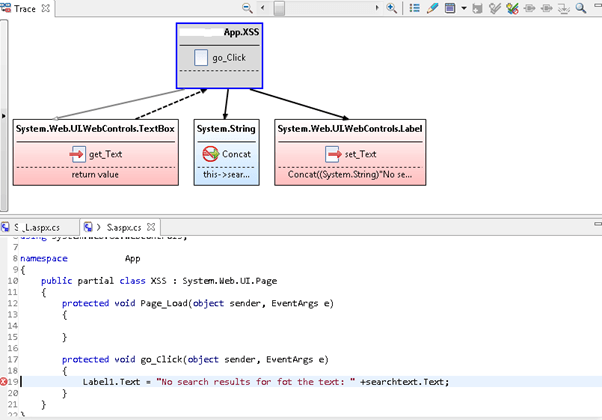
Thus depending on the underlying vulnerability code needs to be analysed in a systematic way to confirm the existence of the issue.
Leave a Reply